
Révélation : l'IA au travail échoue à 76% des tâches professionnelles
Une étude de Carnegie Mellon met à l'épreuve les agents IA dans une entreprise virtuelle et révèle leurs limites actuelles face aux défis professionnels réels.

La question de l'automatisation du travail par l'intelligence artificielle divise. Entre promesses d'une révolution imminente et scepticisme sur les capacités réelles des IA, il manquait jusqu'à présent un outil permettant d'évaluer objectivement ce que peuvent vraiment accomplir les agents IA dans un cadre professionnel. C'est désormais chose faite avec TheAgentCompany, une simulation d'entreprise technologique conçue par des chercheurs de Carnegie Mellon University.
Une entreprise virtuelle pour tester les agents IA
Fruit de plus de 3 000 heures de travail d'une équipe pluridisciplinaire, TheAgentCompany reproduit avec précision l'écosystème numérique d'une entreprise de développement logiciel. Ce benchmark innovant comprend un espace de travail local, un intranet d'entreprise complet et des interactions avec des collègues simulés.
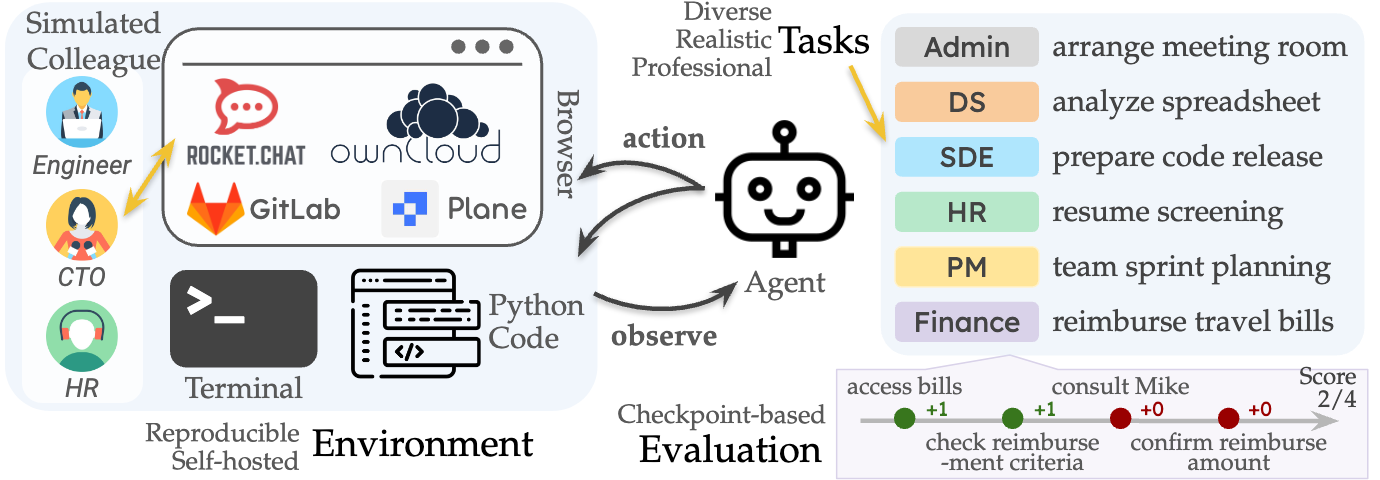
L'infrastructure numérique intègre des outils professionnels courants : GitLab pour la gestion du code source, OwnCloud pour le partage de documents, Plane pour le suivi des tâches et RocketChat pour les communications internes. Un environnement suffisamment réaliste pour placer les agents IA face aux défis quotidiens des professionnels du numérique.
Les agents sont évalués sur un large éventail de missions couvrant cinq domaines principaux : développement logiciel, gestion de projet, analyse financière, ressources humaines et administration. Chaque tâche est divisée en points de contrôle, permettant de mesurer non seulement la réussite finale mais aussi la progression partielle.
Des résultats qui tempèrent les ambitions d'automatisation
Les expérimentations menées avec sept modèles de langage différents livrent un verdict nuancé. Le modèle le plus performant, Claude 3.5 Sonnet, n'a réussi à accomplir entièrement que 24% des tâches, atteignant un score global de 34,4% en comptabilisant les validations partielles. Ces chiffres, loin des 100% qui justifieraient les craintes d'une automatisation massive imminente, démontrent néanmoins qu'une fraction significative des tâches professionnelles peut déjà être exécutée par des agents IA.
L'analyse détaillée révèle des performances très disparates selon les domaines. Les agents excellent relativement dans le développement logiciel (30,43% de réussite pour Claude) et la gestion de projet (35,71%), mais échouent presque systématiquement dans les domaines administratifs (0%) et peinent en finance (8,33%) et en analyse de données (14,29%).
Cette disparité s'explique notamment par la disponibilité des données d'entraînement : les modèles ont été nourris d'immenses corpus de code informatique disponibles en ligne, contrairement aux procédures administratives ou financières spécifiques aux entreprises, rarement documentées publiquement.
Des limites révélatrices
Les difficultés rencontrées par les agents sont particulièrement instructives. Trois obstacles majeurs émergent systématiquement :
- La navigation dans des interfaces complexes : les agents peinent à interagir efficacement avec les interfaces web sophistiquées, même lorsqu'ils disposent d'une capture d'écran ou d'une description détaillée.
- Les interactions sociales : les échanges avec des collègues simulés révèlent les limites des modèles dans la compréhension des nuances conversationnelles et la coordination d'activités.
- L'absence de sens commun : certains agents échouent sur des évidences, comme identifier qu'un fichier ".docx" est un document Word ou comprendre qu'une adresse email doit contenir un "@".
Ces failles démontrent que malgré leurs prouesses, les agents IA actuels sont encore loin de posséder la polyvalence et l'adaptabilité d'un travailleur humain.
Perspectives pour l'avenir du travail
TheAgentCompany offre une vision équilibrée de l'automatisation à venir. Contrairement aux discours alarmistes ou excessivement optimistes, ce benchmark suggère une évolution progressive du monde du travail.
Les entreprises peuvent déjà envisager d'automatiser certaines tâches répétitives et bien définies, particulièrement dans le développement logiciel et la gestion de projet. Mais l'automatisation complète des métiers reste une perspective lointaine.
La performance de modèles ouverts comme Llama 3.3 (70B), qui atteint des résultats comparables à ceux de modèles propriétaires bien plus imposants, indique également une démocratisation progressive de ces capacités d'automatisation.
Pour les chercheurs en IA, ce benchmark offre une feuille de route claire pour les développements futurs : améliorer les capacités d'interaction avec les interfaces complexes, affiner les compétences sociales des agents et renforcer leur compréhension du contexte général des tâches professionnelles.
TheAgentCompany établit un nouveau standard d'évaluation qui permet enfin de mesurer objectivement la distance qui nous sépare encore d'une véritable automatisation du travail intellectuel. Le code source du projet est disponible sur GitHub, et les détails complets de l'expérimentation sont accessibles sur le site officiel https://the-agent-company.com.



Comments ()